
You know what NTFS is… that’s your Windows file system, right?
You probably also know that Linux uses several different file systems, the most extended ones being ext3 and ext4.
Here’s the thing…. there’s an old file system called ZFS, originally designed by SUN Microsystems in 2001 and delivered for the first time as a Solaris product on 2005. At the time, it was a very specific tool designed to serve the needs of a reduced number of companies running large pools of disks sitting in the server room of a corporation’s HQ. It was a very niche FS that very few people would find useful, at the time…
But now it is appearing in many places, from laptops to clusters, and threatening with becoming Linux’s new main FS. Let’s see what all the fuss is about…
What happened between then and now? Why such a niche and old piece of software is coming back?
Well, the Internet became mainstream, allowed cloud computing, then DevOps emerged and then containers exploded; as a consequence of those changes, the needs of system administrators and users alike have completely changed. What used to be a strange and relatively complex file system, tailored for very specific needs and used exclusively by just a few people, in heavily guarded rooms, might have become the best option nowadays and because it was so well architected, 20 years after, it’s now shining more than ever, rapidly growing in adoption and menacing to become mainstream.
ZFS, The Zettabyte File System!
As you can see, even the name of the file system is kind of menacing, worry not, you don’t need Zettabytes of storage to be able to take advantage of ZFS.
What makes ZFS great:
– It’s not just a File System, it’s also a Volume Manager, combining those 2, usually separated applications, gives you a great deal of flexibility and also means ZFS is aware of everything storage in your computer or across computers. You can have one file system that spans several computers with ZFS, pretty cool eh!
– ZFS makes sure your data can live forever, it is designed to take care of most aspects of data longevity problems very effectively. ZFS will detect any data corruption and has data self-healing capabilities to guarantee your file system integrity over time.
– Allows for nearly instant snapshots and data backup, even across remote servers thanks to it’s “copy on write” technology.
– Can roll back your entire storage pool very rapidly, whether it’s just your laptop PC with one single SSD or several Petabytes worth of space stored across multiple servers in several datacenters around the world. And it does it incredibly fast and in a very secure fashion.
– Supports on the fly compression of your data, and it does so before the data is even written to disk, making it one of the fastest file systems in existence.
– Supports on the fly encryption of your data, which happens before the data is written to disk, this feature can be particularly useful if you want your data storage to be fully compliant with EU’s GDPR and maybe one of the easiest ways to implement it to the uttermost degree of compliance.
– Supports many data caching methods, including a very useful and powerful hybrid method that allows your applications to retrieve your most used data, data located on Spinning and slow (but cheap and cost-effective) HDD drives at SSD or NVMe speeds.
– It can deduplicate your data at both, the pool level (cluster) or at the data level (files). Deduplication means that the pieces of data you use again and again are stored only once in the FS cache to save space (usually RAM) https://www.youtube.com/watch?v=E9BpOPX6ap4
– It can cache your already deduplicated and compressed data in memory, making it one of the fastest File Systems available with the smallest footprint for the speed.
– It’s very scalable, given it’s all in one architecture, it’s relatively simple to expand your storage pool, at infinitum and also makes it simple to mix older and newer drive types with different technologies, like Spinning HDD, SSD and NVMe, in fact it allows for hybrid setups where you can take advantage of the best features of each of those technologies.
– ZFS makes software RAID obsolete and since NVMe and Hardware RAID controllers don’t seem to be made for each other, you could argue it also makes Hardware Raid obsolete.
– With the advent of Docker, Kubernetes, microservices and the serverless architecture, you could even argue that this is the only, production ready, cloud file system…
– Ready for the future and big data capable: ZFS designers really considered Moore’s law, ZFS is capable of managing single file sizes of 16 Exabyte and a total storage of 256 quadrillion Zettabytes, Just to give you an idea of what this number means, current (2018) total storage available worldwide including phones, PCs, servers or any other device is supposed to be around 10.000 zettabytes.
– Universal Portability! ZFS provides tools to snapshot your File System, locally or to remote servers. Most importantly, your snapshots can be used in any of the Operating Systems that support ZFS, including any version of Linux, FreeBSD, Solaris, Windows, Mac and some more.
– The extra complexity, adds a great deal of flexibility!
Key concepts for everyday usage and a basic understanding of ZFS:
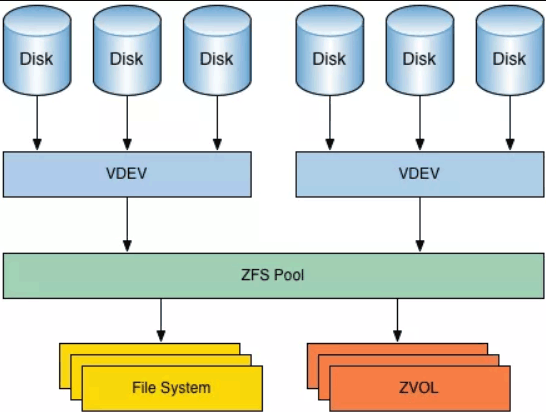
As mentioned before, ZFS is both a file system and a volume manager in one, hence it’s different to more traditional approaches and has its own naming conventions:
– Physical devices such as hard drives and SSDs are called ZVols and organized into groups known as VDEVs (virtual devices).
– VDEVs are more or less equivalent to what we call RAID levels in other File Systems. VDEVs define how the Zvols are going to be used, mirror, stripe, etc… You can group VDEVs together to form ZPOOLs. You can have a one device VDEV. Besides all the standard RAID types, ZFS has a couple VDEV Types (RAID Types) of its own that are really powerful like RAID-Z and Cache device types.
– One Zpool can contain any number of Datasets (Files and directories) and/or Zvols. Zpool groups your storage devices and presents the storage pools as one device to the system. Zpools can be formed out of one single Zvol (disk) or several, it can contain drives and Vdevs of different sizes and it’s very effective at using all sort of different drives, it is also excellent at extracting good performance out of a heterogeneous “pile of disks”.
– A file system is called a Dataset. A dataset is what contains the files and folders and makes them accessible to the OS. This can get a little confusing because we are used to considering the file system to be the root of everything, but in an architecture where storage is fully independent of the system(s) it resides on, it makes a lot of sense.
– ZVOLs or ZFS Volumes are virtual block devices (mostly like your C: disk on a Windows PC or an sda1 device in Linux) that the OS can use as it were a local HDD (remember that physical discs can be, and usually are on a different machine or on a NAS on the network). This feature is what’s most useful for a container-centric architecture because it makes very easy to surface a “chunk” of storage as a local device inside the container and also to virtually move them around as needed.
If it’s so good, why isn’t it the default FS in all OSs?
ZFS has had a hard life, the initial and main realm of ZFS is Solaris, which for other reasons not related to its file system, has had a troublesome history.
At one point, the future of ZFS looked very bright, when Apple announced (2006) to use ZFS as the FS for Mac OS, however this was short lived and, for unknown reasons (legal trouble or corporate “agreements” are suspected) and Apple silently eliminated all traces of ZFS out of MAC OS it in 2009.
ZFS was designed and developed at Sun Microsystems, extensively used in Solaris, Source code was released as part of OpenSolaris in 2005. Sun was later acquired by Oracle, which decided to discontinue OpenSolaris thus making ZFS proprietary, after that it took some time for several Open Source forks to become a reality, ZFS development became fragmented across several independent projects.
In 2008 a new initiative to port ZFS to Linux was started, with some adoption in 2011 and 2012, the first stable version became available in 2013.
Several OSs like FreeBSD and several Linux flavors have supported ZFS since then, FreeBSD and Suse specifically, have had strong implementations for many years; however, I think the definitive push was the inclusion of ZFS in Ubuntu 16 on April 21, 2016. Canonical is making serious efforts to make ZFS a first-class citizen on Ubuntu.
While you can install your OS on top of ZFS as root/boot, it usually is quite an involved endeavor, which requires a decent deal of knowledge about your OS boot process.
For quite some time FreeBSD had this feature, and now Ubuntu has made it even simpler, you can now just choose ZFS as one of the FS at the installation screen.
Right now this is just an experimental feature available on Ubuntu Desktop only, but Canonical has plans to roll it to their Server versions in the near future.
Due to the popularity of Ubuntu and the number of derivative distros from it, this could be the final push needed for ZFS to become the next best FS on Linux.
Update from the Ubuntu blog:
ZFS and zsys
In Ubuntu 19.10, we added experimental support for installing the desktop onto a ZFS formatted filesystem. Ubuntu 20.04 LTS ships with a newer ZFS which features native, hardware-enabled encryption, device removal, pool trim and improved performance. While still experimental, we’ve built upon this feature with the addition of zsys.
zsys is our own integration tool between ZFS and Ubuntu. When users install software or update their system, zsys will take an automatic snapshot, enabling users to roll back, should an update go bad. These snapshots are presented in the GRUB boot menu. This also lays the foundation for additional backup features in the future.
Sadly, ZFS Boot/Root for Ubuntu server hasn’t made it to 20.04 LTS.
Alternatives:
BTRFS (Better FS, Butter FS) is one of the few file systems with a similarly powerful set of features (or even better for some use cases). It has been the promised, new and Linux native, FS standard for Linux, however, it’s not really taking off yet and many are concerned that it never will.
– Performance is worse than ext4 and also worse than ZFS in most use cases.
– It is not production-ready for the datacenter. (Raids 0 and 1 work perfectly but from there up, it’s not ready yet).
– Performance for relational databases is simply terrible, so much so that it becomes unusable for the purpose.
It might certainly have some place in the new microservices / Kubernetes paradigm, for sure, but why use both BTRFS for containers and ZFS for databases when ZFS does both magnificently?
There are also some proprietary alternatives, but we only care about Open Source in this blog.
There is currently an explosion of many new cloud, and even cloud native, storage solutions, to name a few, Ceph, Gluster, Ray, Portworx, OpenEBS. Each offers unique features, mostly centered around the use of Docker containers and Kubernetes. For now, it’s hard to use these in production, some run on top of other FSs and some don’t yet perform well in general. Some are terrible at databases because they tend to use replication, but most of all, I have yet to see any of these new tools doing anything that cannot be done with ZFS.
And those are just proper, traditional but modernized Storage systems for the cloud, some people go further and consider other, completely different types, like Elastic search or even Kafka to be the new generation and future of cloud data storage.
As I see it, the usefulness of all these cloud storage tools is quite limited for Monolithic apps like Mautic, SuiteCRM, and most of the well established, Open Source Marketing Tools we use nowadays.
That’s what makes ZFS, in my opinion, the best Linux File System in existence and the best and most viable option for serving apps on the cloud in a secure, GDPR compliant, reliable way.
Conclusion:
This is one of those cases where 1+1 is much more than 2, ZFS combines a volume manager with a File manager, and takes this magical combo above and beyond. Its unique features greatly improve data resiliency, security and manageability; to the point where, once you start using it, there’s no turning back.
The future of ZFS looks brighter than ever, and while not Linux-native, it might become the new standard FS for Linux Desktops and servers in the following years.
The main downside is getting used to it, because it’s so powerful and capable, it uses several abstractions we are not used to deal with, which can make your first contact with it a little bit daunting.
– For personal computers it might certainly be overkill, the benefits will probably not outweigh the learning curve and the migration efforts needed to adopt it.
– For workstations where multiple disks are used and data resiliency and/or manageability start to take an important role, it makes a lot of sense.
– For servers and especially for Cloud computing, where performance, flexibility, portability, and reliability are top concerns, it is just something you cannot live without.
I use ZFS as root for some of my servers and one VPS (yes you can do that too), however, I really look forward to the day I can just choose ZFS when installing Linux on a new server or as an option on IaaS Providers.
My name is Yosu Cadilla, a Systems Analyst and Platform Engineer for mktg.dev
I discovered Mautic in 2017 and since have specialized in:
– Running Mautic for Marketing Agencies.
– Running large Mautic instances, sometimes with millions of contacts.
– Helping companies build and optimize their (usually Mautic) runtime infrastructure.
If you are planning on deploying Mautic for your Marketing Agency, or you have a large Mautic Instance…
Let’s have a chat! yosu.cadilla@gmail.com


